背景
从计算机发展的早期说起,单核处理器的性能遇到了物理限制,比如散热和时钟频率提升的困难,导致单核性能无法持续提升。这时候,多核处理器和并行计算开始兴起。摩尔定律虽然预测了晶体管数量的增长,但单线程性能不再显著提升,所以转向并行处理成为必然。
科学计算、大数据、人工智能等领域对计算能力的需求激增,传统的串行计算无法满足这些需求,必须依靠并行处理来加速计算。例如,天气预报、基因测序,分子动力学模拟,物理仿真,大模型训练这些需要处理海量数据并需进行大量的数学计算的领域,并行计算能显著缩短计算时间。
并行计算或称平行计算是相对于串行计算来说的。它是一种一次可执行多个指令的算法,目的是提高计算速度,及通过扩大问题求解规模,解决大型而复杂的计算问题。所谓并行计算可分为时间上的并行和空间上的并行。 时间上的并行就是指流水线技术,而空间上的并行则是指用多个处理器并发的执行计。
说到这里我们把并行与并发做比较:
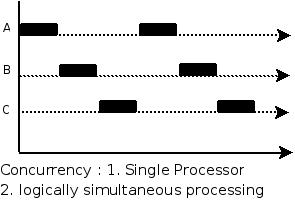
并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。就好像两个人各拿一把铁锨在挖坑,一小时后,每人一个大坑。所以无论从微观还是从宏观来看,二者都是一起执行的。

并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。这就好像两个人用同一把铁锨,轮流挖坑,一小时后,两个人各挖一个小一点的坑,要想挖两个大一点得坑,一定会用两个小时。
并行计算
随着科技的持续发展,现在的计算机上的CPU和GPU都具有快速的计算能力。因此并行技术在CPU和GPU上都在迅速的发展。由于矩阵乘法中每个结果元素的计算都是相互独立的,因此从CPU和GPU的角度出发来说明并行技术在矩阵乘法上面的优势。
串行计算
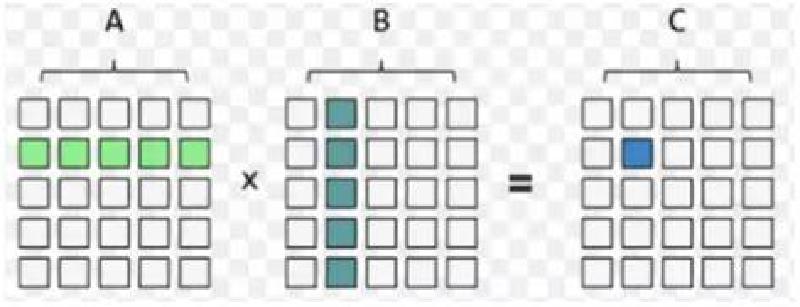
$$ {c_{i,j}} = {a_{i1}}{n_{1j}} + {a_{i2}}{n_{2j}} + ...... + {a_{is}}{n_{sj}}. $$如下图。两个矩阵相乘必须满足A矩阵的列与B矩阵的行相等。

那么在计算机上用C语言实现两个矩阵,这里就不多赘述了,只需要遍历两个矩阵的行和列并求和便可以计算出来,具体代码如下:
|
|
上面算法设置的m,s,n的值均为1000,即为两个1000*1000的方阵相乘。其算法的时间复杂度为${O^3}$,最后的运行结果为
串行运行的时间为:3220.000000ms
在CPU上的并行(MPI+OPENMP)
环境配置
cpu:R5-3500X(6核心6线程)睿频3.59GHz
显卡:RTX 1660super 6G
操作系统:windows10
编程环境:visual studio2022
多线程并行(OPENMP)
单个物理核心通过分时复用技术(如Intel Hyper-Threading)模拟多个逻辑线程,共享核心的计算资源(如ALU、缓存),但独立维护线程的上下文。
多线程并行可以通过C++的std::thread和python的threading来控制线程的创建与同步。OPENMP提供了编译器指令或API接口方便用户能够更快的进行多线程并行。在vs2022中只需要把项目设置中->c/c++->语言->openmp支持改为是就配置好了OpenMp的环境。
|
|
OPENMP提供了标志并行区域的语句#pragma omp parallel for schedule(dynamic)可以使用多个线程并行执行该for语句。该语句会根据线程数量动态的分配for循环的任务。上述代码就是让每一条线程处理C矩阵的一小部分行中所有元素的计算任务实现并行计算。如需要了解其他的OPENMP的语句和功能可以参考OpenMP(使用C++多线程并行计算优化你的程序)入门篇 - 知乎。
串行结果与并行结果性能对比如下:
Hello World 0 from thread = 0 Hello World 1 from thread = 0 Hello World 4 from thread = 2 Hello World 5 from thread = 2 Hello World 8 from thread = 4 Hello World 2 from thread = 1 Hello World 3 from thread = 1 Hello World 6 from thread = 3 Hello World 7 from thread = 3 Hello World 9 from thread = 5 CPU_Serial time: 3199.000000 ms CPU_Parallel time: 542.000000 ms
多进程并行(MPI)
现代CPU包含多个独立的物理核心(如4核、8核等),每个核心具备独立的运算单元(ALU)、寄存器、缓存等资源,能同时执行不同的指令流。
与多线程并行不同的是多进程并行是利用CPU的多个核心或者分布式集群上的多台机器。但是多进程中的数据是互不共享的,如果需要数据传递则需要进程间的通信。那么为了方便多进程编程,MPI为在分布式内存架构下的进程间通信提供了规范和库支持。在程序的角度,MPI就是一系列函数接口,他们可以实现不同进程(不同内存区域)之间的消息传递。在windows环境下,笔者这里选择的是微软的MS-MPI配置MPI环境Downloads | MPICH,然后再vs2022中加入MPI的相关依赖Windows10+VisualStudio2019配置MPI 附在VS中直接运行MPI程序的方法_vs2019如何编译mpi程序-CSDN博客。最后,基于c语言的MPI程序是要通过mpiexec进行编译运行。运行命令为:F:\MPI\Bin\mpiexec.exe -n 4 $(TargetPath),-n 4表明并行的进程数。
|
|
在MPI程序设计中通过MPI_Init(&argc, &argv), MPI_Finalize() 来标志并行区域,每个进程都会执行这段并行区域的代码。上述代码中规定进程0用来初始化矩阵,打印消息,而从进程(1,2,3)用来计算矩阵的元素。由于各个进程之间的数据都是独立的,因此主进程需要把需要计算的数据发送到从进程去计算并且从进程计算好的结果需要发送到主进程中汇总打印输出。
i % (numprocs-1)+1按行数平均分配任务到各个从进程中
MPI_Send,MPI_Recv发送数据到其他进程,接收其他进程发送的数据
虽然运行的进程数是4,但是实际参与计算的进程数只有3。最后运行的性能结果如下:
MPI并行运行的时间为:1493.000000ms
在GPU上的并行(CUDA)
可以看到GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。因此,基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效
CUDA是NVIDIA公司所开发的GPU编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序。CUDA提供了对其它编程语言的支持,如C/C++,Python,Fortran等语言,这里我们选择CUDA C/C++接口对CUDA编程进行讲解。
|
|
cudaMallocHost,cudaMalloc分别表示在在CPU的分配内存,和在CPU分配内存
cudaMemcpy可以从CPU的内存数据拷贝到GPU的内存中,或者拷贝GPU的内存的数据到CPU内存中
kernel是CUDA中一个重要的概念,kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用matMultCUDAKernel1<<<grid, block>>>来指定kernel要执行的线程数量,在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
-
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步 -
__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用 -
__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译
dim 用力定义GPU的gird大小和block大小
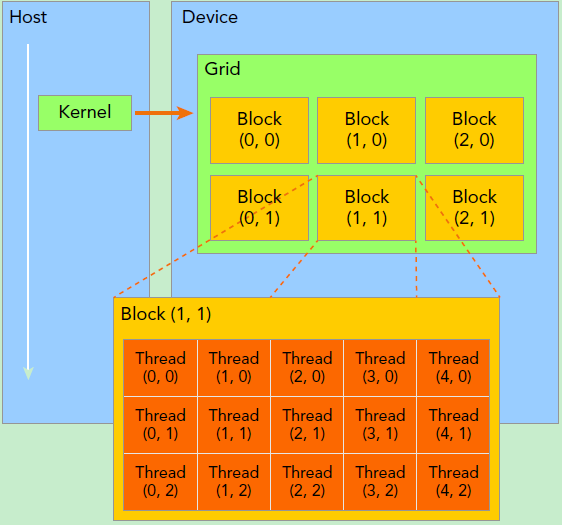
matMultCUDAKernel1核函数中通过 blockIdx , threadIdx,blockDim确定某个线程的二维索引,这与举证相乘正好对应。因此可以用GPU一个线程的对应的二维索引(row,col)处理对应的A矩阵的第row行与B矩阵的第col列相乘。这个线性计算完成后把计算结果放在C矩阵中的第row行第col列。最后输出结果如下:
Device Name : NVIDIA GeForce GTX 1660 SUPER. totalGlobalMem : 2147024896. sharedMemPerBlock : 49152. regsPerBlock : 65536. warpSize : 32. memPitch : 2147483647. maxThreadsPerBlock : 1024. maxThreadsDim[0 - 2] : 1024 1024 64. maxGridSize[0 - 2] : 2147483647 65535 65535. totalConstMem : 65536. major.minor : 7.5. clockRate : 1830000. textureAlignment : 512. deviceOverlap : 1. multiProcessorCount : 22. GPU memory: 7.629395e+00 MB GPU time: 43.000000 ms CPU time: 3337.000000 ms Max error: 1.19209e-07 Average error: 1.1436e-09